
📓1. 熵和互信息
1.1 信息的介绍
信息论由克劳德·香农(Claude E. Shannon,1916-2001)通过《通信的数学理论》(A Mathematical Theory of Communication),发表于1948年《贝尔系统技术期刊》创立。
什么是信息?一些观察如下:
信息源自不确定性。
信息应与可能性的数量相关。
信息应具有“可加性”。
我们可以使用对数来缩小大量的可能性。
二进制排列用于表示所有的可能性。
信息的度量应考虑各种可能事件的概率。
因此,信息是:接收者未知的知识,是对不确定性的度量。
定义:给定消息 M1,M2,...,Mq,其发生的概率为 P1,P2,...,Pq(P1+P2+...+Pq=1),则每条消息所携带的信息量的度量为
x=2,:I(Mi)单位是bit(比特)
x=e,:I(Mi)单位是nats(奈特)
x=10,:I(Mi)单位是Hartley(哈特莱)
信息量的性质:
当 Pi→1 时,I(Mi)→0;
当 0≤Pi≤1 时,I(Mi)≥0;
如果 Pj>Pi,则 I(Mi)>I(Mj);
若 Mi 和 Mj 统计独立,则 I(Mi&Mj)=I(Mi)+I(Mj)
1.2 熵
给定长度为 N 的源向量。它有 U 个可能的符号 S1,S2,...,SU,每个符号出现的概率分别为 P1,P2,...,PU。要表示该源向量,我们需要
平均而言,
H 称为源熵,表示每个源符号的平均信息量。它也可以理解为函数 log2Pi−1 的期望值:
不同底数的熵可以通过以下方式互换:
证明如下:
现在我们考虑两个随机变量 X 和 Y 的熵,X 和 Y 的取值分别为 x 和 y。X和 Y 的分布分别为 P(x) 和 P(y)。因此我们有:
联合熵 H(X,Y):给定联合分布P(x,y)
条件熵 H(Y∣X):
链式法则(联合熵与条件熵的关系):
证明如下:
如果 X 和 Y 独立:
因此
该链式法则可以推广为:
1.3 互信息
我们有两个随机变量 X 和 Y,X 和 Y 的取值分别为 x 和 y。X 和 Y 的分布分别为 P(x) 和 P(y)。X 和 Y 的联合分布为 P(x,y)。
互信息 I(X,Y) 的定义为:
由以下关系可知:
因此:
注意:如果 X 和 Y 独立,P(x)P(y)=P(x,y),则 I(X,Y)=0。
互信息与熵的关系:
证明如下:
该证明还表明了互信息的对称性:
该关系也可以通过维恩图可视化表示。
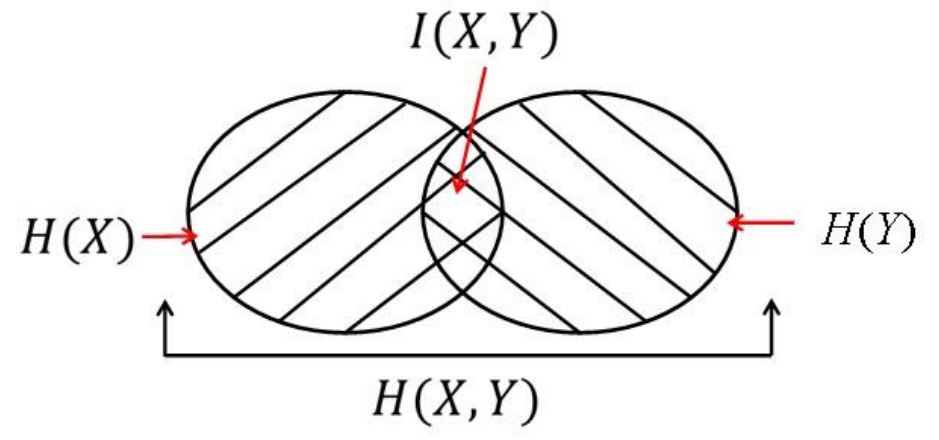
推论:
结论如下:
0≤I(X,Y)≤minH(X),H(Y);
如果 H(X)⊂H(Y),则 I(X,Y)=H(X)。类似地,如果 H(Y)⊂H(X),则 I(X,Y)=H(Y);
I(X,X)=H(X)−H(X∣X)=H(X),熵也称为自信息。
对于互信息,任意多个变量的链式法则如下:
假设 X 是传输信号,Y 是接收信号。
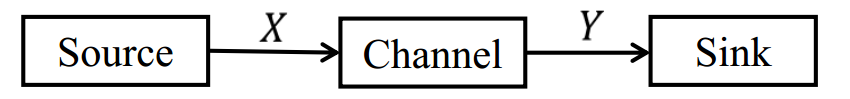
互信息 I(X,Y) 描述了一个变量 X 包含关于另一个变量 Y 的信息量,或反过来为 I(Y,X)。
1.4 信息论的进一步结果
相对熵:假设 X 和 X 是两个随机变量,取值分别为 x 和 x。它们旨在描述同一事件,其概率质量函数分别为 P(x) 和 P(x^)。它们的相对熵定义为:
相对熵通常称为两个分布 P(x) 和 P(x) 之间的 Kullback-Leibler(KL 距离)。
当假设分布为 P(x^) 而真实分布为 P(x) 时,它是一种低效性的度量。例如,事件可以用平均长度为 H(P(x)) 位描述。然而,如果我们假设其分布为 P(x),我们需要平均长度为 H(P(x))+D(P(x),P(x^)) 位来描述它。
它不是对称的,即 D(P(x),P(x^))=D(P(x^),P(x))。
推论 1:
推论 2:
证明如下:
凸函数:若函数 f(x) 在区间 (a,b) 上是凸的,即对于 x1,x2∈(a,b) 且 0≤λ≤1,有:
当且仅当 λ=0 或 λ=1 时,等号成立,则该函数为严格凸函数。
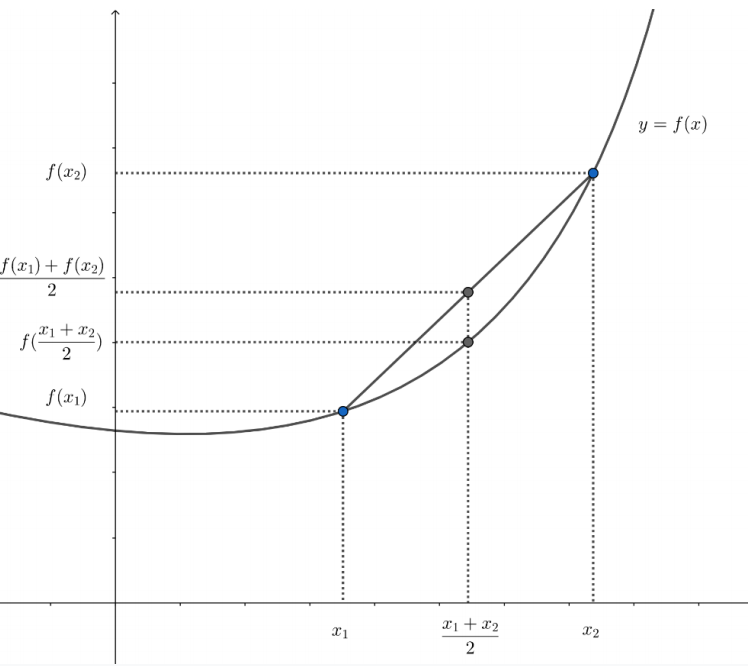
如果 f(x) 是凸函数,则 −f(x) 是凹函数。
詹森不等式:如果函数 f(x) 是凸的,则有:
詹森不等式可以用于证明一些关于熵的性质。
推论 2: D(P(x),P(x^))≥0
推论 3: I(X,Y)≥0
仅当 P(x,y)=P(x)P(y) 时,I(X,Y)=0,即 X 和 Y 独立。
推论 4(最大熵分布):
给定变量 X∈x1,x2,...,xU,其分布为 P1,P2,...,PU。我们有:
证明:
由于 log2(⋅) 是一个凹函数,基于詹森不等式,我们有:
注意:如果 X 在 x1,x2,...,xU 上均匀分布,即 P1=P2=⋯=PU=U1,则有:
费诺不等式:设 X 和 Y 是两个随机变量,其取值来自 x1,x2,...xk。设 Pe=Pr[X=Y],则有:
证明:我们构造一个二元变量 Z得:
因此
因此,H(Z)=H(Pe)。基于熵的链式法则:
注意,已知 X 和 Y 时,Z 是确定的,且 H(Z∣XY)=0。同样基于链式法则:
因此
注意:H(Pe) 是在 X=Y 时描述 X 所需的比特数;log2(k−1) 是在 X=Y 时描述 X 所需的比特数。当 X 在所有 k−1 个值上均匀分布时,等号成立。
信息处理不等式:给定一个串联的数据处理系统:

马尔可夫链 X→Y→Z 表示在给定 Y 的情况下,X 和 Z 条件独立,因此有以下关系:
因此我们有
得
证明:
数据处理无法增加信息。
Last updated